Hadoop
NTTデータはHadoopなどの並列分散処理技術についての
豊富な知見で、お客様のデータ活用をトータルにご支援します。
SOLUTION Hadoop
NTTデータのHadoopソリューション
NTTデータのソリューションとは
NTTデータは、大規模データの活用にHadoopを利用した、分散処理のアプローチで多くの実績があります。
従来は夜間時間帯で実行していたバッチ処理を高速化することで、より早く情報を活用できる機会を創りました。
また、機器の容量不足などにより数日間分で捨てていたデータを数か月~年単位で保存することで、分析の精度を高めることができるようになりました。
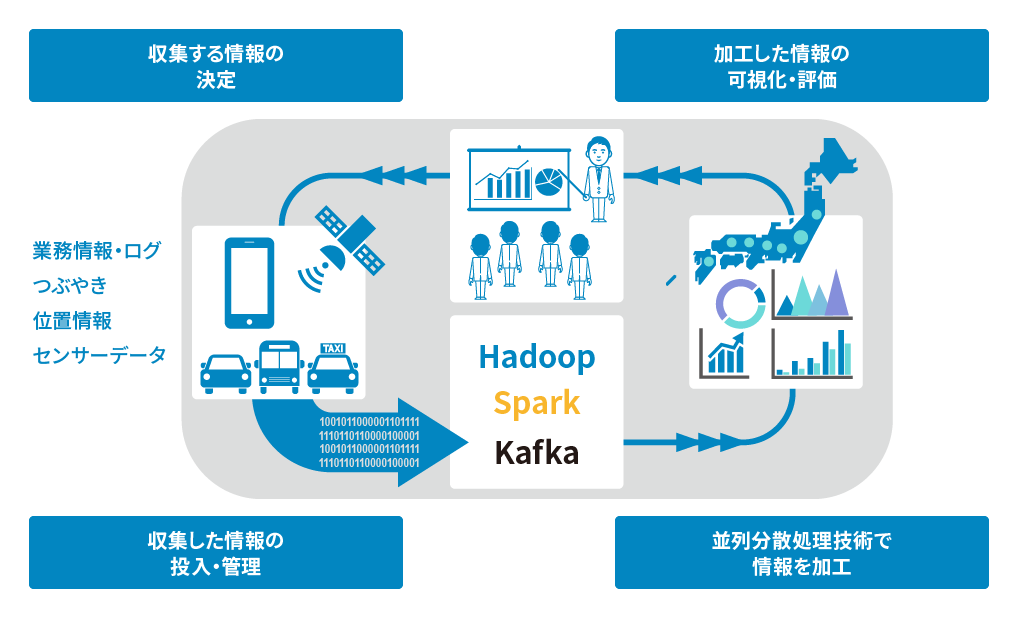
実現したいことに応じて、数台~千台規模のサーバーからなるHadoopシステムを導入するなどの実績がございます。 加えて、データの活用シーンに応じて様々な分散処理環境を提供してきた実績もございます。 そして、数年以上のHadoopシステム運用で得られたノウハウを蓄積しています。
分散処理技術HadoopについてHadoop, Spark, Kafkaを利用した分散処理システムに強み
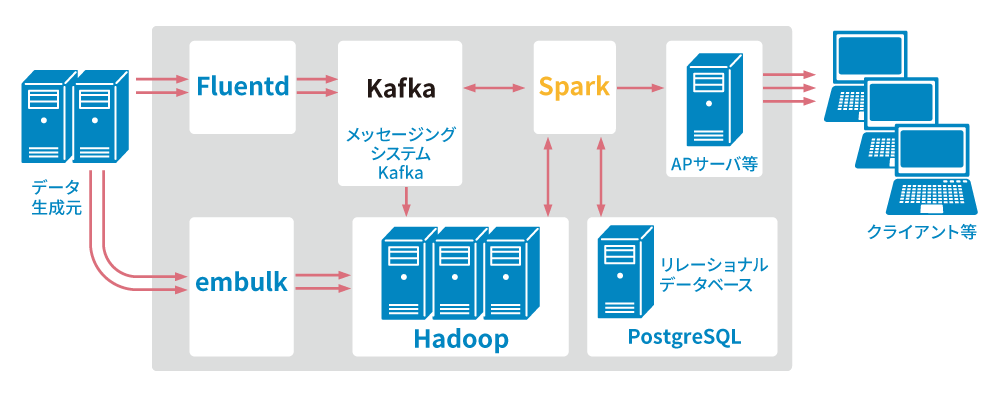
NTTデータでは、Hadoopをはじめとしたオープンソースソフトウェアを適切に組み合わせることで、最適な分散処理基盤を提供します。
例えば、データ入力にFluentd、メッセージングシステムとしてKafka、データの蓄積にHadoop、データの処理にSparkを利用し、基盤全体をカバーすることで、分散処理基盤を実現します。
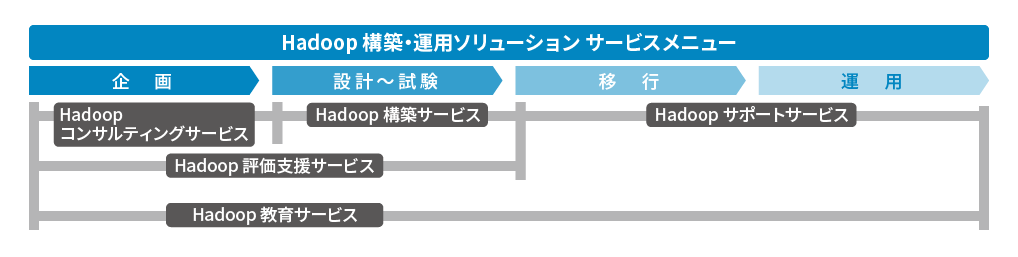
「Hadoop構築・運用ソリューション」サービス
NTTデータでは、Hadoopに関する各種ソリューションサービスを提供します。
| Hadoop コンサルティングサービス |
お客様が保有する多種多様なデータの活用し、新たな価値を生み出すために、専門技術者がご支援いたします。 提案支援、システム化コンサルティング、設計書レビューなど、まずはご相談ください。 |
|---|---|
| Hadoop評価支援サービス | 実機を用いてHadoopを評価したいというお客様を、専門技術者がご支援いたします。 検証方法のご提案~結果の分析、チューニング観点のアドバイスなどを行います。 |
| Hadoop構築サービス | 十数~数千台の構築経験を活かして、専門技術者がHadoopシステムの構築を実施します。 最適な機器選びからチューニングまで、トータルにご支援いたします。 |
| Hadoopサポートサービス | Hadoopの保守契約です。基本サポート内容はメールベースの技術問い合わせ・故障問い合わせ対応です。 保守プロダクトは、Hadoop、Spark、Kafkaをはじめとするオープンソースソフトウェアです。 オプションとしてオンサイトの故障対応も実施します。ご希望の方はお問い合わせください。 |
| Hadoop教育サービス | 「社内にHadoop技術者を育成したい」等、プライベートセミナをご希望の方はお問い合わせください。 |
Hadoop & Spark 構築・運用ソリューションの特長
-
特長1
データをHadoopへ蓄積するところから、活用するところまでトータルに支援します
大規模データ活用は、単にHadoopを導入すれば実現できるわけではありません。データをHadoopにどのように蓄積するか、Hadoopエコシステムとの組み合わせ、Sparkなど他の並列分散処理技術との使い分けなど、考慮すべき事がたくさんあります。NTTデータは、それら全てをトータルにご支援します。
-
特長2
並列分散処理に長けた技術者が高速な大量データ処理を安定運用させます
NTTデータは他社に先駆けて2008年よりHadoopに取り組み、数台~千台規模のHadoop基盤の構築やペタバイト級のデータを扱う等、国内最大規模の構築・運用実績を保持しています。Hadoopの開発コミュニティでも活躍する技術者が、実システムで得られた豊富な知見をもってお客様の大量データ処理を安定運用させます。
-
特長3
小さくはじめて、大きく育てる。PoCからはじめられます
並列分散処理のための特殊なサーバやストレージは不要です。 小規模から始めて、必要な容量や処理性能に応じて拡張可能です。 最近では商用システム導入前のPoCのご相談も増えています。何かございましたらお気軽にお問い合わせください
Hadoopで実現!「大量データの蓄積~活用」「バッチ処理時間の高速化」
オープンソースの並列分散処理基盤「Hadoop」 を数台~千台規模で構築・運用したノウハウを活用し、 他の仕組みでは実現が難しいお客様のデータ活用をご支援いたします。 ビッグデータ活用をご検討の方、既存のバッチ処理の長時間化にお困りの方に対し、 オープンソースの並列分散処理基盤「Hadoop」のコンサルティングから、PoC、システム構築、運用設計、導入後の サポートまで幅広く提供いたします。
case1 ビックデータ活用(大量・大規模データ処理)
アクセスログやセンサデータ等「全て」蓄積し、全件分析を現実的な時間で実施 →新たなサービスの検討や、迅速な戦略立案
【Point】
サンプリングデータではなく全てのデータを蓄積し、分析できます。
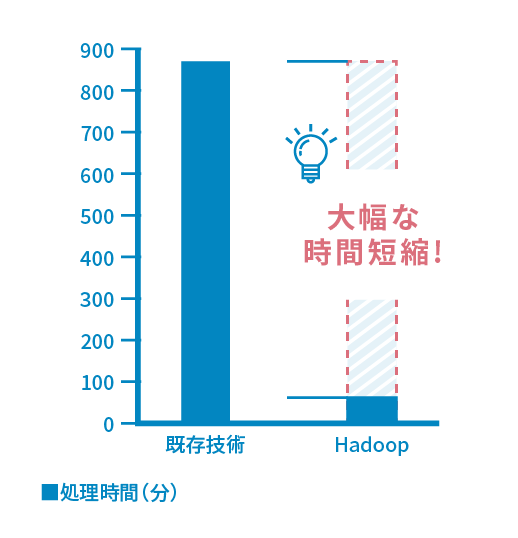
case2 既存バッチ処理の高速化
専用ホスト上のバッチ処理をコモディティサーバ上で大幅に短縮化→コスト対効果の高いバッチ処理基盤に
【Point】
Hadoopは、全件走査を必要とするバッチ処理を手堅く高速処理できます。 公共/金融分野の基幹バッチ処理にも適用可能です。