Hadoop
ABOUT Hadoop
分散処理技術「Hadoop」とは
分散処理技術「Hadoop」とは
Hadoopとは、大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェアです。 Apacheプロジェクトの元で、Hortonworks社、米国Yahoo!社、Cloudera社といった初期から参加していた企業に加えて、 Intel社、Microsoft社などより多くの企業のメンバーによって開発が続けられています。
Hadoop登場の背景
Hadoopは、Google社が論文として公開した、Google社内の以下の基盤技術をオープンソースとして実装したものを利用しています。
- * GFS (Google File System : Google社の分散ファイルシステム)
- * Google MapReduce (Google社での分散処理技術)
検索サービスで扱うWebページの情報をGFSに保存して、検索用インデックスをGoogle MapReduceで生成する などの用途で利用されました。 これらの論文をもとに、Doug Cutting氏(現在、Apacheコミュニティの議長)を中心としたメンバーがJavaベースで開発したものが始まりです。 Doug氏たちは、Hadoopとして以下のコンポーネントを開発しました。そして、現在に至っています。
- * HDFS (Hadoop Distributed File System : Hadoop分散ファイルシステム)
- * Hadoop MapReduce Framework(Hadoop MapReduceフレームワーク)
なお、Hadoopという名前は、Doug氏のお子さんが持っていたお気に入りの象のぬいぐるみの名前を利用しています。
Hadoopの特長
Hadoop分散処理基盤の代表的な特長は、以下の通りです。
-
特長1
単純なサーバの追加によってスケーラビリティを実現
HDFSの容量や分散処理のためのリソースが不足する場合、サーバを追加することで容量および処理性能の向上が可能です。 サーバの追加はHadoopクラスタの停止を必要としません。サービスを継続した状態での運用が可能です。 また、アプリケーションや基盤設計に影響を及ぼすことなく、新たにスケーラビリティを得ることができます。

-
特長2
非定型データの格納を想定した処理の柔軟性を実現
従来型のRDBMSやDWHと根本的に異なる点は、HDFSにデータを格納する際にはスキーマ定義が不要であることです。 そのため、事前の設計の手間を低減することができます。 Hadoopでは、処理するタイミングでHDFSに格納したデータにその都度意味づけするので、 とりあえず格納して、処理の方針が決まった際にデータの扱い方を定義することができます。
-
特長3
コモディティ品の利用を前提とした基盤構成・耐障害性
Hadoop環境を構成するサーバは、専用ハードウェアや特別なスペックを必要としません。 そのため、市販で入手できるサーバを利用することで、基盤構築の費用を抑えられます。
また、大量のサーバを利用する際には、サーバ故障時の扱いに気を付けなければなりませんが、 Hadoopは故障発生を前提としたアーキテクチャであるため、任意のサーバが故障しても システム全体として問題なく動作します。
Hadoopを構成するコンポーネント
Hadoopは、分散ファイルシステムであるHDFS(Hadoop分散ファイルシステム)と分散処理フレームワークであるHadoop MapReduceの2つから構成されます。
HDFS
HDFSは、マスターノードであるNameNodeとスレーブノードであるDataNodeで構成されています。 NameNodeは分散ファイルシステムのメタ情報を管理し、DataNodeは、データの実体を保存します。 HDFSにファイルを格納する場合、そのファイルを一定サイズで分割したデータをブロックとしてDataNodeで保存します。
また、任意のDataNodeが故障し、そのDataNodeで保存されているブロックが消失する可能性を考慮して、 ブロックは、複数のDataNodeにレプリカを保存します。これにより、任意のDataNodeが壊れた場合でも、 他のDataNodeの同じブロックを参照することができ、データの欠損を防ぐ仕組みになっています。 HDFSは、デフォルトで3つのレプリカをDataNodeで保存します。このレプリカ数は、HDFSに格納するファイル単位で変更することが可能です。
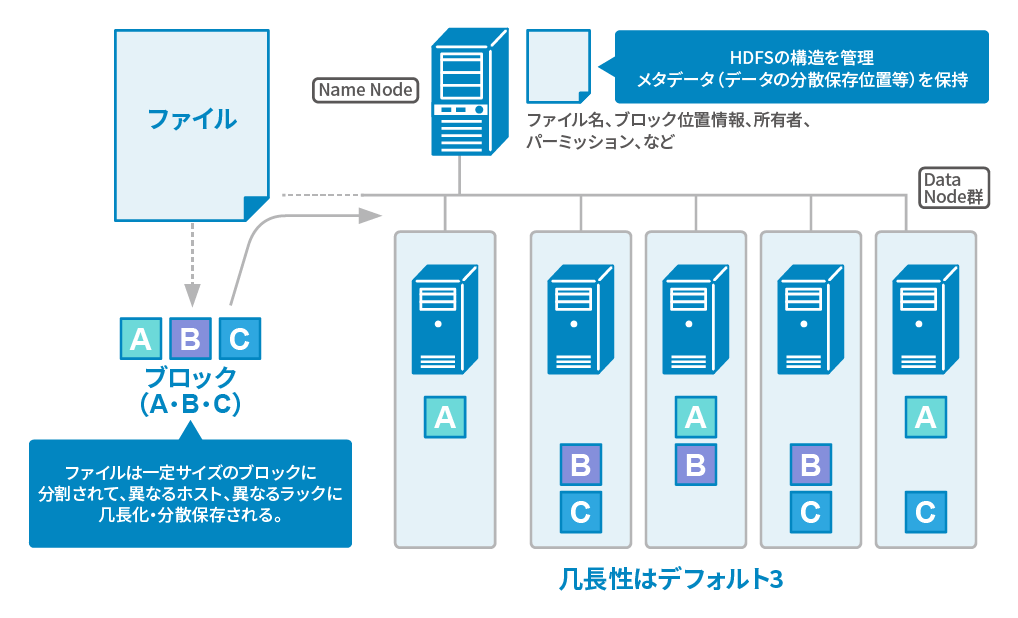
HDFSは、DataNodeの故障に対しては、ブロックのレプリカを保存しているため、レプリカを持つすべてのDataNodeが同時に故障しない限り、
サービスを継続することは可能です。しかし、NameNodeは単一のノードであるため、故障した場合にはHDFSのサービスを継続することはできません。
以前のHadoop(1系)では、NameNodeの単一故障点に対して、他のOSSを組み合わせて、サービス停止時間を小さくするような取り組みがありました。
NameNodeのサービスを維持する仕組みとして、Apache
ZooKeeperの分散ロック機構を利用した、Active-Standby構成のNameNode-HAが開発されました。
このNameNode-HAにより、Active側のNameNodeが故障した場合に、ダウンタイムなしでStandby側のNameNodeにサービスを引き継げることが可能になりました。
HDFSは、POSIXライクなファイルシステムです。HDFSの操作はCLI(コマンドラインインターフェース)や、REST、Java-APIなどで実現できます。 コマンド体系は、UNIXやLinuxのコマンドを操作した場合と類似しているため、これまでの知見をHDFS操作にも利用できると言えます。
HDFSは、利用者の任意のデータを分散ファイルシステム上で保存することが可能です。 また、保存する際に、特別な作業は不要です。 HDFSは、その仕組み上、サイズが大きいファイルを格納する点について、その威力を発揮します。 一方、次のような利用には不向きと言えます。
(1) 多数のサイズが小さいファイルを格納
HDFSのメタ情報はNameNodeで管理するため、多数の小さなファイルを格納するとリソースを無駄遣いすることになります。HDFSでは、小さなファイルを結合して、少ない大きなファイルとして格納する方が望ましいです。
(2) ファイルの更新
HDFSでは、保存しているファイルに対して追記のみ利用することができます。 ファイルの途中を更新して保存する仕組みは提供されていません。その場合は、ローカル環境でファイルを更新した後、更新したファイルをHDFSに保存して上書きすることになります。
Hadoop MapReduce
Hadoop MapReduceは、分散処理を実現するMapReduce処理基盤と処理基盤上で実行するMapReduceアプリケーションの2つのコンポーネントがあります。
Hadoop MapReduce処理基盤
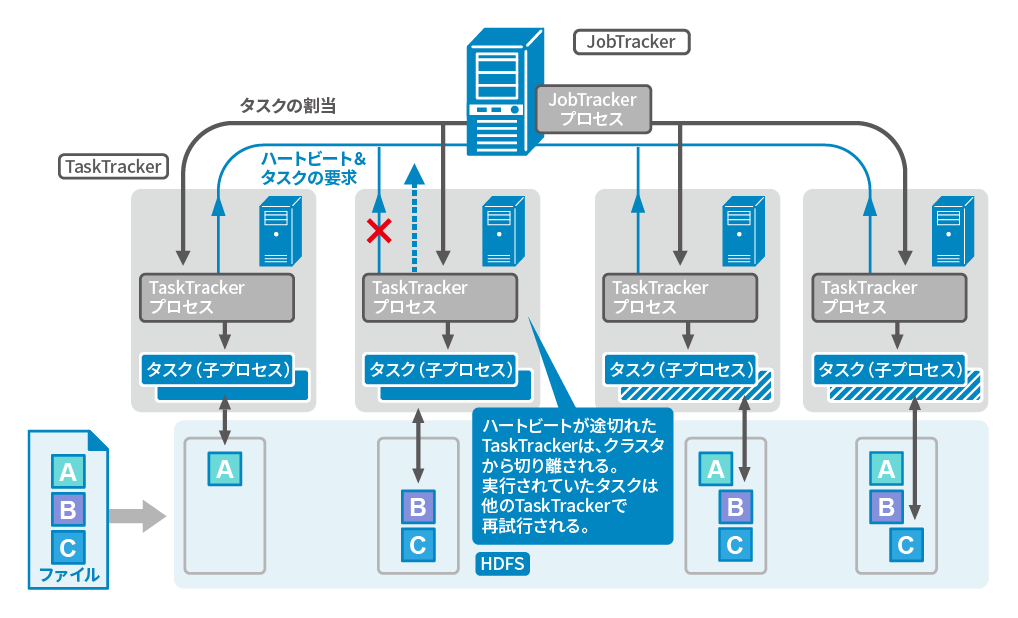
Hadoop MapReduceは、マスターノードであるJobTrackerとスレーブノードであるTaskTrackerで構成されています。
JobTrackerは、MapReduceジョブの管理やTaskTrackerへのタスクの割り当て、TaskTrackerのリソース管理を役割としています。
TaskTrackerは、タスクの実行を役割としています。
MapReduce処理基盤では、TaskTrackerが故障し、そのTaskTrackerで実行していたタスクが完了できない場合は、JobTrackerは他のTaskTrackerに
同じタスクを割り当てます。これによりMapReduceジョブ全体を最初からやり直す必要がなく、継続して実行することが可能です。
JobTrackerが、TaskTrackerにタスク(mapタスク)を割り当てる際には、そのTaskTrackerが動作しているサーバと同居しているDataNodeが管理しているデータを
極力利用するように割り当てます。これをデータのローカリティと呼びます。
TaskTrackerと同居しているDataNodeのデータを利用することで、サーバ間の通信量を極力抑えることが可能となり、オーバヘッドを抑えます。
一方、reduceタスクは複数のTaskTrackerからデータを取得する必要があるため、mapタスクのようなデータのローカリティを考慮できません。
Hadoop MapReduceアプリケーション
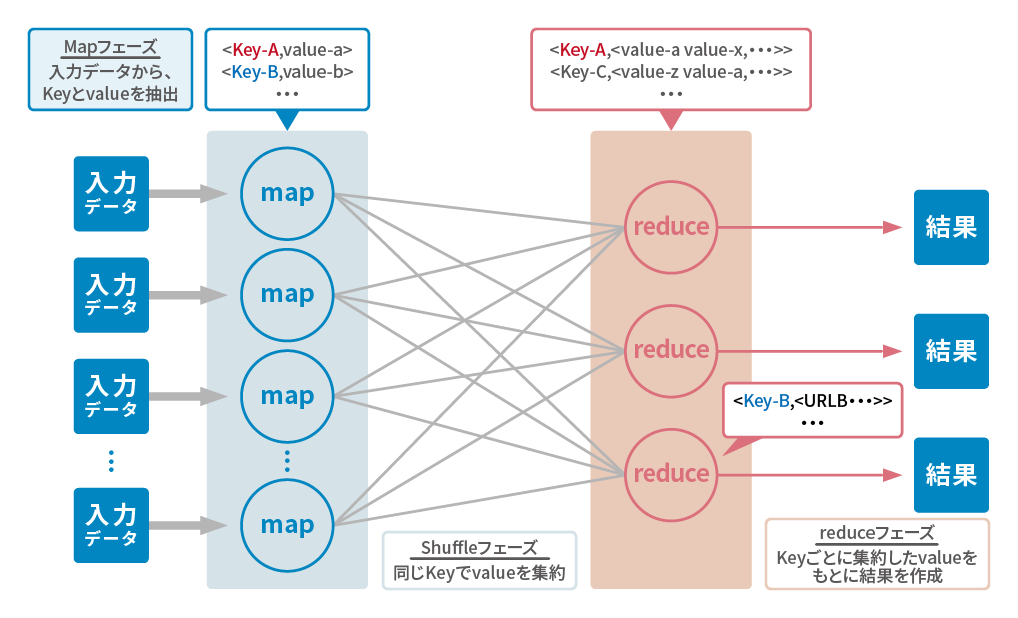
MapReduceアプリケーションは、MapReduce処理基盤上で動作するMapReduceジョブから構成されています。MapReduceジョブでは、主に以下の処理を定義します。
- (1) map処理: 入力データに対して、何らかの処理によってキー・バリューの形式でデータを意味づける
- (2) reduce処理: map処理のキーごとに集約されたデータに対して何らかの処理を実行する
- (3) MapReduceジョブ定義: (1)と(2)を処理するための情報(入力パス、出力パス、reduce処理の多重度など)を定義する
(※ その他、入力データの読み込み方、出力データの書き込み方、個別にデータ型なども必要に応じて利用できます。)
分散処理と言えば、処理情報の共有のための通信、ファイル操作など処理に必要な操作についても複雑な実装が必要です。 Hadoopは、これらの実装をHadoop内部で実現しているため、MapReduceジョブを定義する利用者は、複雑な実装を意識しなくても処理を定義できます。
なお、HadoopのMapReduceアプリケーションは、バッチ処理の用途で利用することを想定して開発されています。 MapReduceジョブの実行は、最短でも10秒程度の時間を要します。 そのため、RDBMSで特定のデータをミリ秒オーダで抽出するような処理には向きません。
Hadoop YARN
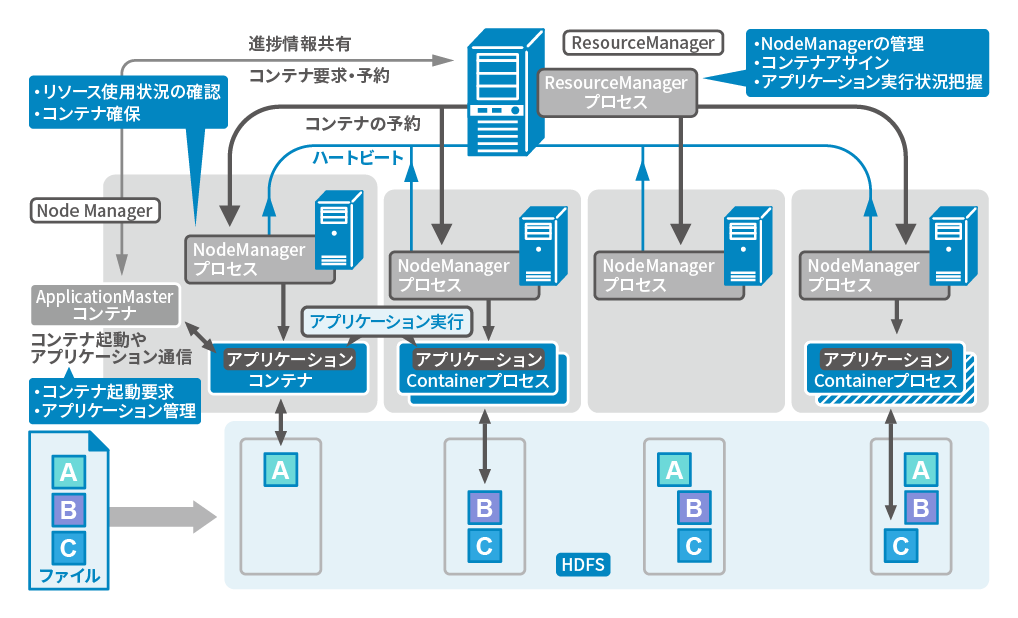
Hadoop2系では、分散処理フレームワークHadoop MapReduceの仕組みが変更となり、分散リソース制御機構 Hadoop YARNとMapReduce ApplicationMasterの2つに分離されました。 YARNの登場により、MapReduceに適していない処理については、各自が仕組み(ApplicationMasterとアプリケーション制御)を実装することでMapReduceと同様にYARNの仕組みによって分散処理が可能となりました。 YARN上でのMapReduce以外のアプリケーションでは、Apache Tez、Apache Sparkなど活発に開発されています。
YARNでは、Hadoopクラスタ内のリソースを管理するマスタノードとしてResourceManager、処理ノードを管理するスレーブノードとしてNodeManagerで構成されています。 アプリケーションを管理するノードApplicationMasterは、リソース状況を確認しつつ処理を実行するContainer(コンテナ)の確保をResourceManagerに要求します。 ResourceManagerは、NodeManagerからのリソース利用状況をもとに、どのノードでContainerを起動するか情報を回答します。 この回答を従い、ApplicationMasterは処理ノードでコンテナ起動を要求してアプリケーションを実行します。
YARNの仕組みによって、アプリケーションの集中管理によるマスタノードのボトルネックが解消され、より多数の処理ノードによりHadoopクラスタを構成することが可能になりました。 Hadoop 1系での仕組みでは3000~4000ノードがクラスタの限界でしたが、YARNの仕組みによって10000ノード程度のクラスタも構成することが可能です。
 お問い合わせ
お問い合わせ